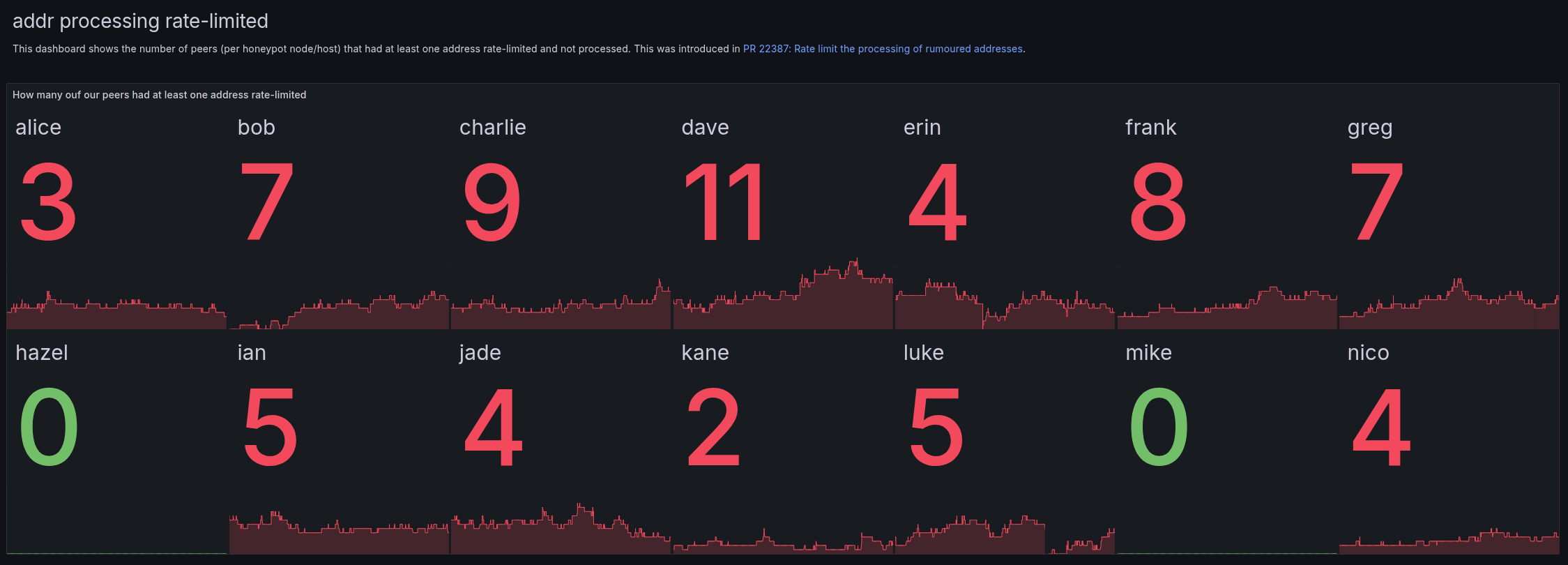
On my peer-observer monitoring, I have a dashboard with the number of connected peers that have at least one address rate-limited. For each node (ignoring hazel and mike with different configurations), it shows a few peers that have been rate-limited.
Looking into this, I it seems like this mostly happens right after the connection is established as the peer doesn’t have enough tokens. The following log snippet contains
an example:
04:12:02 [net] Added connection to [redacted] peer=1234
...
04:12:03 [net] Received addr: 1 addresses (1 processed, 0 rate-limited) from peer=1234
04:12:34 [net] Received addr: 4 addresses (3 processed, 1 rate-limited) from peer=1234
04:13:09 [net] Received addr: 2 addresses (2 processed, 0 rate-limited) from peer=1234
The peer starts with token=1 and uses one for its self-announcement at 04:12:03. Until the next addr message arrives at 04:12:34, it re-gains 3 tokens and uses them, however, the fourth address in this addr message is rate-limited. At 04:13:09, the peer has token=3 and uses 2.
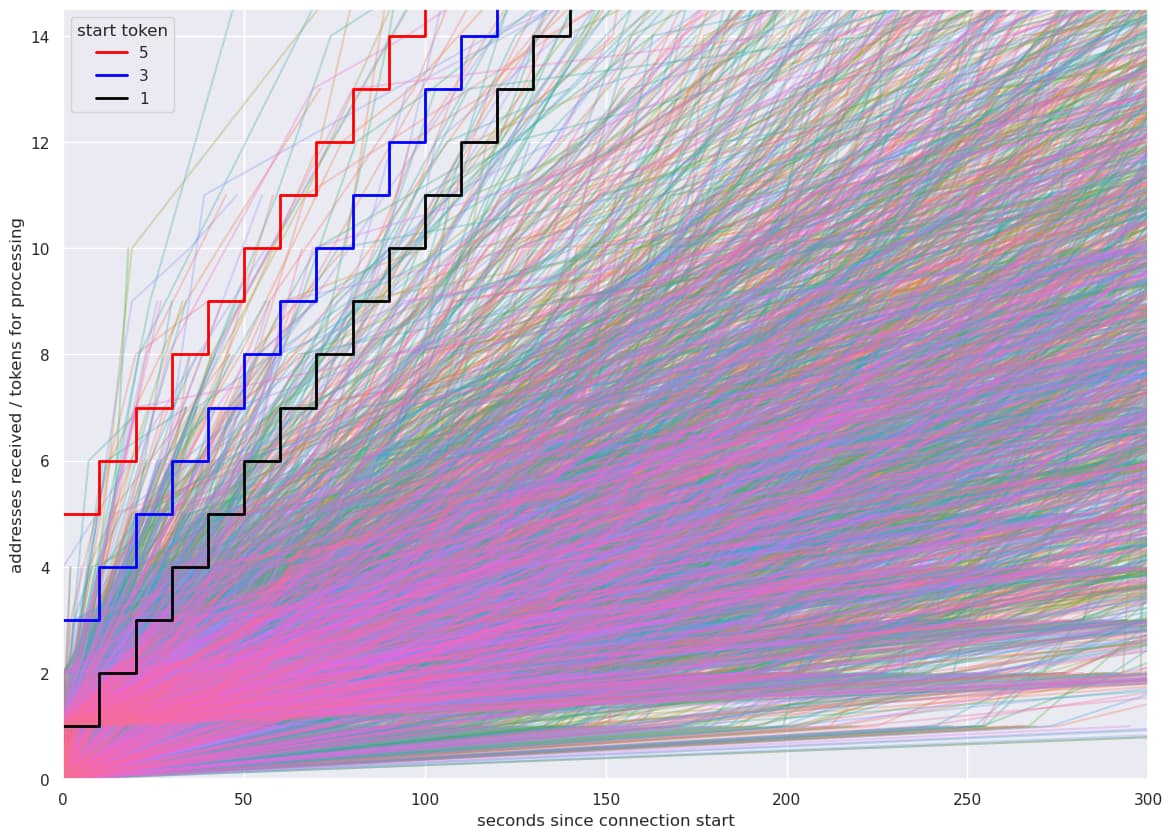
Analyzing logs by sampling from multiple nodes over a time-span of 3 days, it becomes visible that starting with 5 tokens (red step line) rather than 1 token (black step line) and keeping the same rate of 1 new token every 10 seconds would help to drastically reduce false-positives.
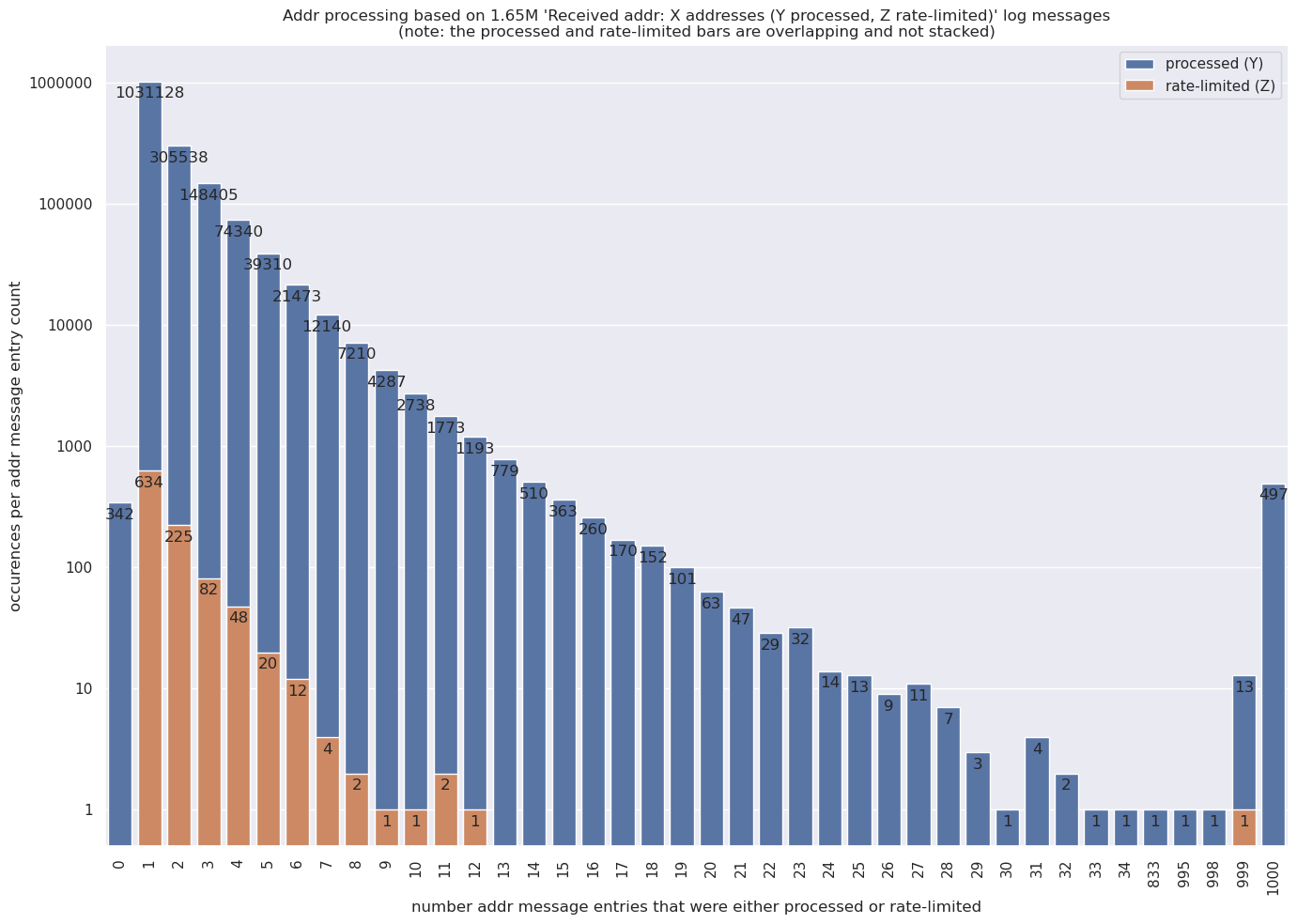
why would an entry get rate-limited with 999 entries? Buggy peer? Why would we be receiving 833, 995, 998, or 999 entries in a single message instead of just 1,000 every time?
Also, I’d expect more than 497 instances of 1,000 entries in ADDR especially when you compare that with the ~1M instances of 1 entry. Especially since we should receive 1,000-entry ADDR message per outbound connection?
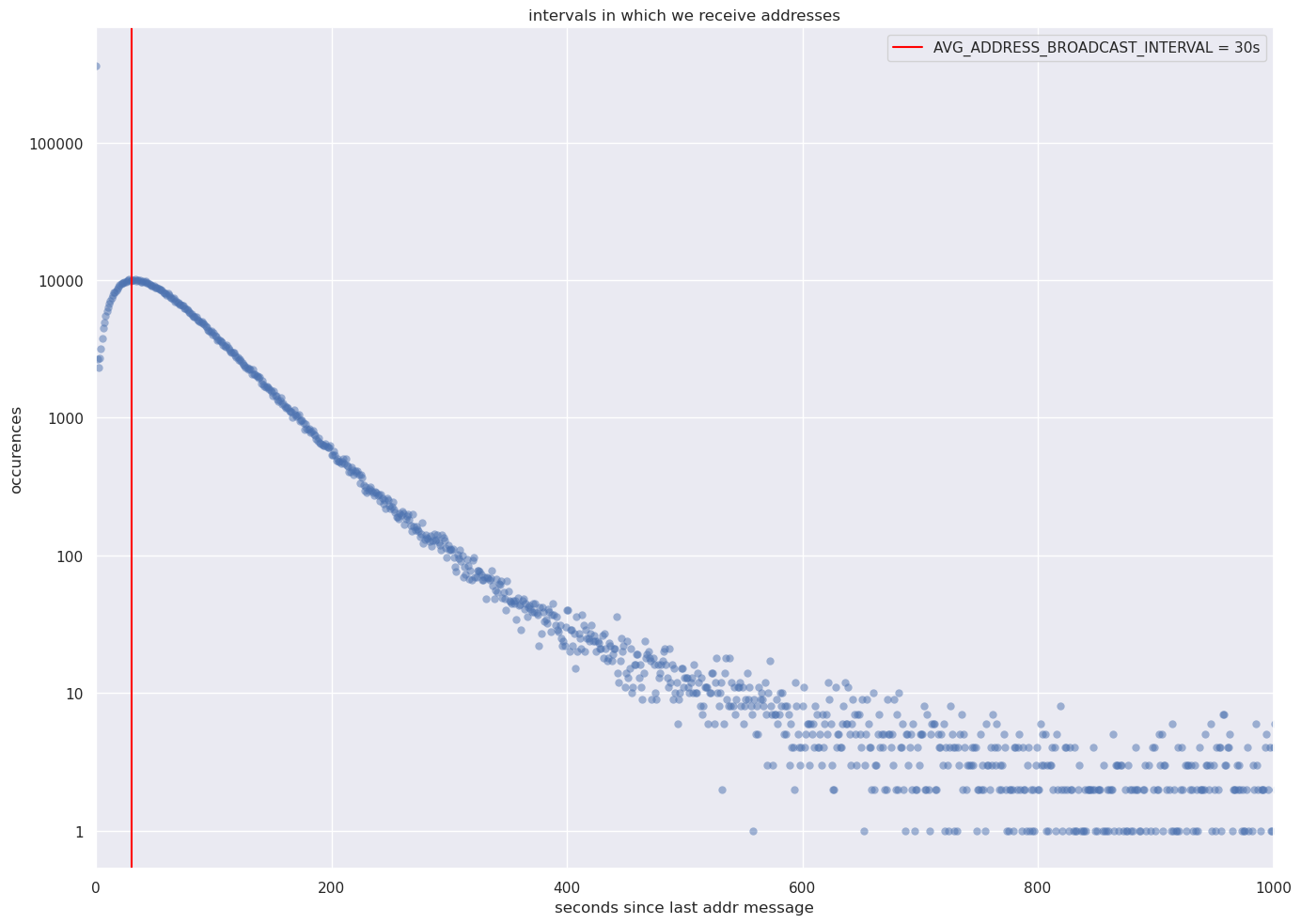
Also looked at the interval in which we receive addresses.
I think this is because the exponential timer does not have a cap, so it is possible (but unlikely) for the timer to be way past the 30s mark. I’m wondering if there should be cap for this. There are other places where `rand_exp_duration` is used:
feelers (avg: 2min)
extra-block-relay peer (avg: 5min)
extra-network peer (avg: 5min)
local address broadcast (avg: 24h!)
fee filter (avg: 10min)
The feefilter one could be an issue sometimes if fees are rising or falling and the next broadcast is like an hour (or more) into the future?
This isn’t so unexpected to me. ADDR messages with 1 entry are typically gossip relay of someone’s self-announcement (not necessarily originating from the peer itself), and both inbound and outbound peers can send gossip ADDRs every 30s ( AVG_ADDRESS_BROADCAST_INTERVAL) - we receive a GETADDR answer only once in the lifetime of a connection, and that only with a full outbound peer. Since we don’t make so many new full outbound connections once we have found a stable set of peers (some exceptions such as stale-tip extra outbound every now and then exist) a much higher number of gossip ADDRS makes sense to me.