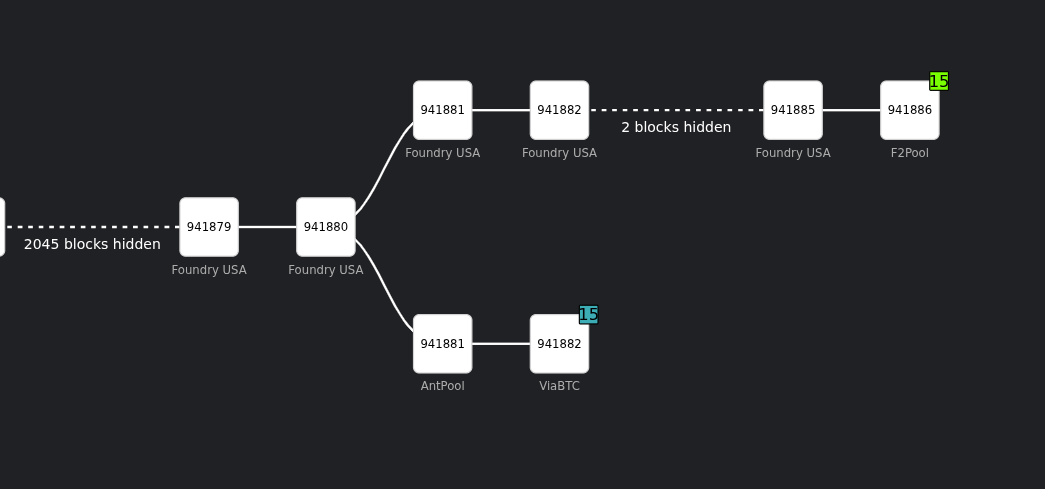
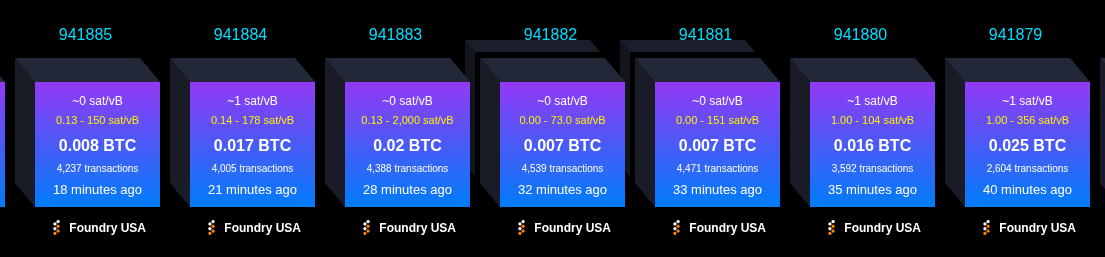
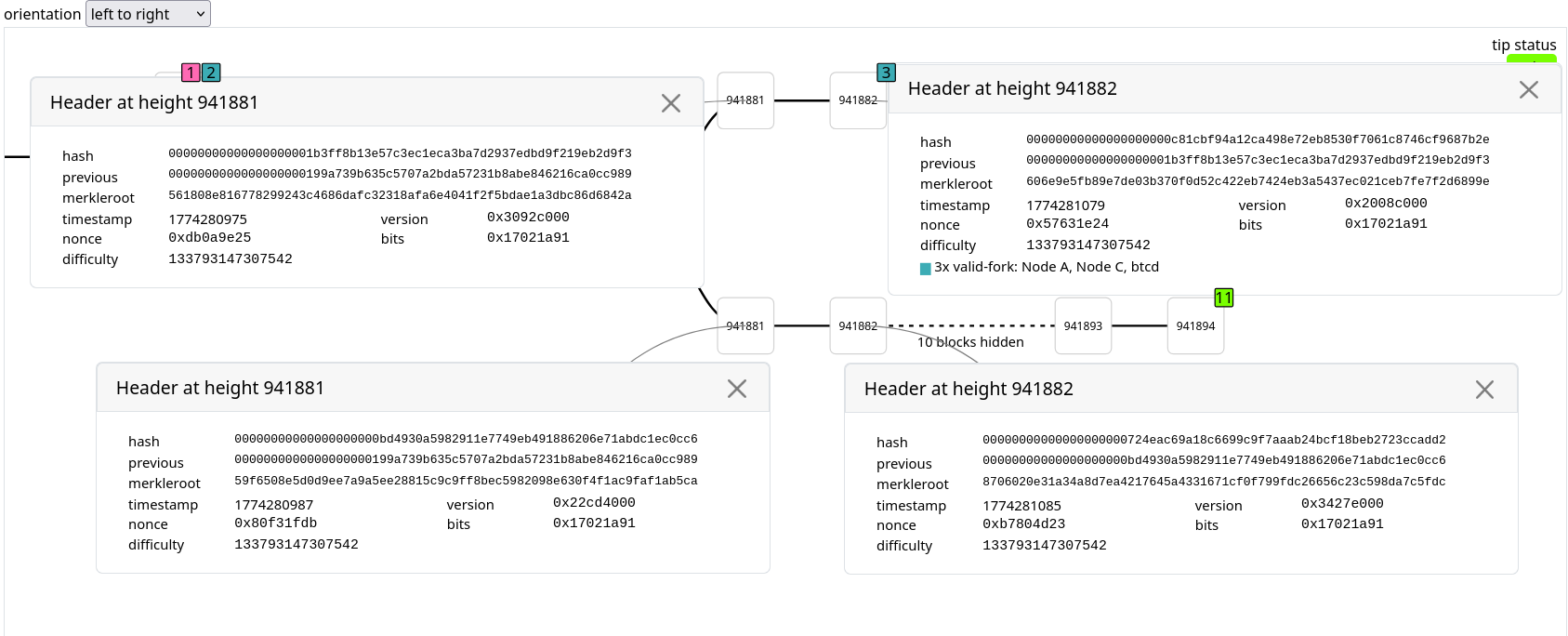
| 15:49:53.834 |
Antpool 1 |
INV |
199 |
|
2026-03-23T15:49:53.834333Z [msghand] [../../src/net_processing.cpp:4146] [ProcessMessage] [net] got inv: block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 new peer=199 |
| 15:49:53.835 |
Antpool 1 |
GETHEADERS |
|
199 |
2026-03-23T15:49:53.834575Z [msghand] [../../src/net_processing.cpp:4190] [ProcessMessage] [net] getheaders (941880) 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 to peer=199 |
| 15:49:54.176 |
Antpool 1 |
HEADERS |
3952229 |
|
2026-03-23T15:49:54.175539Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new header hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 height=941881 peer=3952229, peeraddr=[2600:1702:7aa0:10b0:266e:96ff:fe46:9218]:35822 |
| 15:49:54.176 |
Antpool 1 |
GETDATA |
|
3952229 |
2026-03-23T15:49:54.175654Z [msghand] [../../src/net_processing.cpp:2876] [HeadersDirectFetchBlocks] [net] Requesting block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 from peer=3952229 |
| 15:49:54.282 |
Antpool 1 |
CMPCTBLOCK |
3 |
|
2026-03-23T15:49:54.280740Z [msghand] [../../src/net_processing.cpp:3575] [ProcessMessage] [net] received: cmpctblock (27910 bytes) peer=3 \n 2026-03-23T15:49:54.281870Z [msghand] [../../src/blockencodings.cpp:61] [InitData] [cmpctblock] Initializing PartiallyDownloadedBlock for block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 using a cmpctblock of 27910 bytes |
| 15:49:54.305 |
Antpool 1 |
GETBLOCKTXN |
|
3 |
2026-03-23T15:49:54.305168Z [msghand] [../../src/blockencodings.cpp:178] [InitData] [cmpctblock] Initialized PartiallyDownloadedBlock for block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 using a cmpctblock of 27910 bytes \n 2026-03-23T15:49:54.305744Z [msghand] [../../src/net.cpp:4078] [PushMessage] [net] sending getblocktxn (93 bytes) peer=3 |
| 15:49:54.356 |
Antpool 1 |
CMPCTBLOCK |
3952229 |
|
2026-03-23T15:49:54.354679Z [msghand] [../../src/net_processing.cpp:3575] [ProcessMessage] [net] received: cmpctblock (27910 bytes) peer=3952229 \n 2026-03-23T15:49:54.355897Z [msghand] [../../src/blockencodings.cpp:61] [InitData] [cmpctblock] Initializing PartiallyDownloadedBlock for block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 using a cmpctblock of 27910 bytes |
| 15:49:54.379 |
Antpool 1 |
GETBLOCKTXN |
|
3952229 |
2026-03-23T15:49:54.378914Z [msghand] [../../src/blockencodings.cpp:178] [InitData] [cmpctblock] Initialized PartiallyDownloadedBlock for block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 using a cmpctblock of 27910 bytes \n 2026-03-23T15:49:54.379443Z [msghand] [../../src/net.cpp:4078] [PushMessage] [net] sending getblocktxn (93 bytes) peer=3952229 |
| 15:49:54.425 |
Antpool 1 |
BLOCKTXN |
3 |
|
2026-03-23T15:49:54.425321Z [msghand] [../../src/net_processing.cpp:3575] [ProcessMessage] [net] received: blocktxn (21507 bytes) peer=3 |
| 15:49:54.433 |
Antpool 1 |
CMPCTBLOCK Reconstructed |
3 |
|
2026-03-23T15:49:54.432974Z [msghand] [../../src/blockencodings.cpp:228] [FillBlock] [cmpctblock] Successfully reconstructed block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 with 1 txn prefilled, 4510 txn from mempool (incl at least 0 from extra pool) and 56 txn (21474 bytes) requested |
| 15:49:54.723 |
Antpool 1 |
Update Tip |
|
|
2026-03-23T15:49:54.722505Z [msghand] [../../src/validation.cpp:2867] [UpdateTipLog] UpdateTip: new best=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 height=941881 version=0x3092c000 log2_work=96.137382 tx=1327000957 date=‘2026-03-23T15:49:35Z’ progress=1.000000 cache=218.5MiB(1597395txo) |
| 15:50:01.464 |
Foundry 1 |
INV |
199 |
|
2026-03-23T15:50:01.463926Z [msghand] [../../src/net_processing.cpp:4146] [ProcessMessage] [net] got inv: block 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 new peer=199 |
| 15:50:01.464 |
Foundry 1 |
GETHEADERS |
|
199 |
2026-03-23T15:50:01.464206Z [msghand] [../../src/net_processing.cpp:4190] [ProcessMessage] [net] getheaders (941881) 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 to peer=199 |
| 15:51:47.071 |
Antpool 2 |
INV |
199 |
|
2026-03-23T15:51:47.070886Z [msghand] [../../src/net_processing.cpp:4146] [ProcessMessage] [net] got inv: block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e new peer=199 |
| 15:51:47.071 |
Antpool 2 |
GETHEADERS |
|
199 |
2026-03-23T15:50:01.464206Z [msghand] [../../src/net_processing.cpp:4190] [ProcessMessage] [net] getheaders (941881) 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 to peer=199 |
| 15:51:47.075 |
Antpool 2 |
CMPCTBLOCK |
1271642 |
|
2026-03-23T15:51:47.074890Z [msghand] [../../src/net_processing.cpp:3575] [ProcessMessage] [net] received: cmpctblock (5773 bytes) peer=1271642 \n 2026-03-23T15:51:47.075326Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new cmpctblock header hash=00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e height=941882 peer=1271642, peeraddr=[2600:8801:2f80:ac:f522:7bf5:2ae7:47fd]:60099 \n 2026-03-23T15:51:47.075428Z [msghand] [../../src/blockencodings.cpp:61] [InitData] [cmpctblock] Initializing PartiallyDownloadedBlock for block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e using a cmpctblock of 5773 bytes |
| 15:51:47.08 |
Antpool 2 |
HEADERS |
1271642 |
|
2026-03-23T15:51:47.075326Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new cmpctblock header hash=00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e height=941882 peer=1271642, peeraddr=[2600:8801:2f80:ac:f522:7bf5:2ae7:47fd]:60099 |
| 15:51:47.079 |
Antpool 2 |
CMPCTBLOCK Reconstructed |
|
|
2026-03-23T15:51:47.089420Z [msghand] [../../src/blockencodings.cpp:228] [FillBlock] [cmpctblock] Successfully reconstructed block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e with 1 txn prefilled, 871 txn from mempool (incl at least 1 from extra pool) and 0 txn (0 bytes) requested |
| 15:51:47.176 |
Antpool 2 |
UpdateTip |
1271642 |
|
2026-03-23T15:51:47.175709Z [msghand] [../../src/validationinterface.cpp:182] [UpdatedBlockTip] [validation] Enqueuing UpdatedBlockTip: new block hash=00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e fork block hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 (in IBD=false) |
| 15:51:47.270 |
Foundry 1 |
HEADERS |
199 |
|
2026-03-23T15:51:47.269999Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new header hash=00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 height=941881 peer=199, peeraddr=80.251.125.221:46532 |
| 15:55:01.161 |
Foundry 2 |
INV |
199 |
|
2026-03-23T15:55:01.160946Z [msghand] [../../src/net_processing.cpp:4146] [ProcessMessage] [net] got inv: block 00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 new peer=199 |
| 15:55:01.161 |
Foundry 2 |
GETHEADERS |
|
199 |
2026-03-23T15:55:01.161244Z [msghand] [../../src/net_processing.cpp:4190] [ProcessMessage] [net] getheaders (941882) 00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 to peer=199 |
| 15:55:01.358 |
Foundry 3 |
INV |
199 |
|
2026-03-23T15:55:01.357525Z [msghand] [../../src/net_processing.cpp:4146] [ProcessMessage] [net] got inv: block 000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e new peer=199 |
| 15:55:01.583 |
Foundry 2 |
HEADERS |
199 |
|
2026-03-23T15:55:01.583065Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new header hash=00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 height=941882 peer=199, peeraddr=80.251.125.221:46532 |
| 15:55:01.583 |
Foundry 1 |
GETDATA |
|
199 |
2026-03-23T15:55:01.583122Z [msghand] [../../src/net_processing.cpp:2876] [HeadersDirectFetchBlocks] [net] Requesting block 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 from peer=199 |
| 15:55:01.583 |
Foundry 2 |
GETDATA |
|
199 |
2026-03-23T15:55:01.583148Z [msghand] [../../src/net_processing.cpp:2876] [HeadersDirectFetchBlocks] [net] Requesting block 00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 from peer=199 |
| 15:55:06.356 |
Foundry 3 |
HEADERS |
8302907 |
|
2026-03-23T15:55:06.355712Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new header hash=000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e height=941883 peer=8302907, peeraddr=67.85.54.88:56666 |
| 15:55:06.356 |
Foundry 3 |
GETDATA |
8302907 |
|
2026-03-23T15:55:06.355875Z [msghand] [../../src/net_processing.cpp:2876] [HeadersDirectFetchBlocks] [net] Requesting block 000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e from peer=8302907 |
| 15:55:07.295 |
Foundry 3 |
BLOCK |
8302907 |
|
2026-03-23T15:55:07.294834Z [msghand] [../../src/net_processing.cpp:4859] [ProcessMessage] [net] received block 000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e peer=8302907 |
| 16:02:30.919 |
Main 4 |
INV |
199 |
|
2026-03-23T16:02:30.919287Z [msghand] [../../src/net_processing.cpp:4146] [ProcessMessage] [net] got inv: block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 new peer=199 |
| 16:02:30.920 |
Main 4 |
GETHEADERS |
|
199 |
2026-03-23T16:02:30.919581Z [msghand] [../../src/net_processing.cpp:4190] [ProcessMessage] [net] getheaders (941883) 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 to peer=199 |
| 16:02:30.970 |
Main 4 |
HEADERS |
6312471 |
|
2026-03-23T16:02:30.969996Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new header hash=0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 height=941884 peer=6312471, peeraddr=[fc57:be98:b90c:89a2:6807:69a0:827:947e]:43692 |
| 16:02:30.970 |
Main 4 |
GETDATA |
6312471 |
|
2026-03-23T16:02:30.970148Z [msghand] [../../src/net_processing.cpp:2876] [HeadersDirectFetchBlocks] [net] Requesting block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 from peer=6312471 |
| 16:02:31.324 |
Main 4 |
CMPCTBLOCK |
1283269 |
|
2026-03-23T16:02:31.323094Z [msghand] [../../src/net_processing.cpp:3575] [ProcessMessage] [net] received: cmpctblock (24495 bytes) peer=1283269 \n 2026-03-23T16:02:31.323969Z [msghand] [../../src/blockencodings.cpp:61] [InitData] [cmpctblock] Initializing PartiallyDownloadedBlock for block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 using a cmpctblock of 24495 bytes |
| 16:02:31.342 |
Main 4 |
GETBLOCKTXN |
|
1283269 |
2026-03-23T16:02:31.341592Z [msghand] [../../src/net.cpp:4078] [PushMessage] [net] sending getblocktxn (773 bytes) peer=1283269 |
| 16:02:32.049 |
Main 4 |
BLOCKTXN |
1283269 |
|
2026-03-23T16:02:32.028760Z [msghand] [../../src/net_processing.cpp:3575] [ProcessMessage] [net] received: blocktxn (267997 bytes) peer=1283269 |
| 16:02:32.049 |
Main 4 |
CMPCTBLOCK Reconstructed |
|
|
2026-03-23T16:02:32.049006Z [msghand] [../../src/blockencodings.cpp:228] [FillBlock] [cmpctblock] Successfully reconstructed block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 with 1 txn prefilled, 3268 txn from mempool (incl at least 76 from extra pool) and 736 txn (267962 bytes) requested |
| 16:04:49.393 |
Main 5 |
INV |
199 |
|
2026-03-23T16:04:49.393196Z [msghand] [../../src/net_processing.cpp:4146] [ProcessMessage] [net] got inv: block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f new peer=199 |
| 16:04:49.393 |
Main 5 |
GETHEADERS |
|
199 |
2026-03-23T16:04:49.393406Z [msghand] [../../src/net_processing.cpp:4190] [ProcessMessage] [net] getheaders (941884) 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f to peer=199 |
| 16:04:49.595 |
Main 5 |
HEADERS |
4392345 |
|
2026-03-23T16:04:49.594756Z [msghand] [../../src/net_processing.cpp:3546] [LogBlockHeader] Saw new header hash=00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f height=941885 peer=4392345, peeraddr=10.30.1.77:55010 |
| 16:04:49.595 |
Main 5 |
GETDATA |
|
4392345 |
2026-03-23T16:04:49.594846Z [msghand] [../../src/net_processing.cpp:2876] [HeadersDirectFetchBlocks] [net] Requesting block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f from peer=4392345 |
| 16:04:50.220 |
Main 5 |
BLOCK |
|
4392345 |
2026-03-23T16:04:50.219701Z [msghand] [../../src/net_processing.cpp:4859] [ProcessMessage] [net] received block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f peer=4392345 |
| 16:05:01.590 |
Foundry 1 |
Block stall timeout, disconnect peer |
199 |
|
2026-03-23T16:05:01.590359Z [msghand] [../../src/net_processing.cpp:6110] [SendMessages] Timeout downloading block 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6, disconnecting peer=199, peeraddr=80.251.125.221:46532 |
| 16:05:01.612 |
Foundry 1 |
GETDATA |
|
8302907 |
2026-03-23T16:05:01.611937Z [msghand] [../../src/net_processing.cpp:6181] [SendMessages] [net] Requesting block 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 (941881) peer=8302907 |
| 16:05:01.612 |
Foundry 2 |
GETDATA |
|
8302907 |
2026-03-23T16:05:01.611964Z [msghand] [../../src/net_processing.cpp:6181] [SendMessages] [net] Requesting block 00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 (941882) peer=8302907 |
| 16:05:02.593 |
Foundry 1 |
BLOCK |
8302907 |
|
2026-03-23T16:05:02.592967Z [msghand] [../../src/net_processing.cpp:4859] [ProcessMessage] [net] received block 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 peer=8302907 |
| 16:05:03.322 |
Foundry 2 |
BLOCK |
8302907 |
|
2026-03-23T16:05:03.321989Z [msghand] [../../src/net_processing.cpp:4859] [ProcessMessage] [net] received block 00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 peer=8302907 |
| 16:05:03.434 |
Antpool 2 |
Block Disconnected |
|
|
2026-03-23T16:05:03.433595Z [scheduler] [../../src/validationinterface.cpp:239] [operator()] [validation] BlockDisconnected: block hash=00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e block height=941882 |
| 16:05:03.844 |
Foundry 1 |
Update Tip |
|
|
2026-03-23T16:05:03.843581Z [msghand] [../../src/validation.cpp:2867] [UpdateTipLog] UpdateTip: new best=00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 height=941881 version=0x22cd4000 log2_work=96.137382 tx=1327000861 date=‘2026-03-23T15:49:47Z’ progress=0.999990 cache=219.0MiB(1599154txo) |
| 16:05:04.065 |
Foundry 2 |
Update Tip |
|
|
2026-03-23T16:05:04.065420Z [msghand] [../../src/validation.cpp:2867] [UpdateTipLog] UpdateTip: new best=00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 height=941882 version=0x3427e000 log2_work=96.137391 tx=1327005400 date=‘2026-03-23T15:51:25Z’ progress=0.999993 cache=219.3MiB(1602981txo) |
| 16:05:04.355 |
Foundry 3 |
Update Tip |
|
|
2026-03-23T16:05:04.355114Z [msghand] [../../src/validation.cpp:2867] [UpdateTipLog] UpdateTip: new best=000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e height=941883 version=0x2fc2e000 log2_work=96.137401 tx=1327009788 date=‘2026-03-23T15:54:49Z’ progress=0.999995 cache=219.8MiB(1607191txo) |
| 16:05:04.425 |
Antpool 1 |
Block Disconnected |
|
|
2026-03-23T16:05:04.424781Z [scheduler] [../../src/validationinterface.cpp:239] [operator()] [validation] BlockDisconnected: block hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 block height=941881 |
| 16:05:08.862 |
Main 4 |
Update Tip |
|
|
2026-03-23T16:05:08.862000Z [msghand] [../../src/validation.cpp:2867] [UpdateTipLog] UpdateTip: new best=0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 height=941884 version=0x212b4000 log2_work=96.137410 tx=1327013793 date=‘2026-03-23T16:02:14Z’ progress=0.999998 cache=220.3MiB(1610860txo) |
| 16:05:09.152 |
Main 5 |
Update Tip |
|
|
2026-03-23T16:05:09.152296Z [msghand] [../../src/validation.cpp:2867] [UpdateTipLog] UpdateTip: new best=00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f height=941885 version=0x22abe000 log2_work=96.137420 tx=1327018030 date=‘2026-03-23T16:04:46Z’ progress=1.000000 cache=220.8MiB(1614193txo) |